Jak działa React – Virtual DOM, Fibers, Reconciliation
Witaj w kolejnym wpisie z serii poświęconych bibliotece React. W poprzednim materiale przedstawiłem czym on jest, do czego służy i jakie zalety (oraz wady) mogą z niego wyniknąć. Zanim przejdziemy do samego kodu należy jeszcze poznać nieco zasadę działania mechanizmów React. Pozwoli to na lepsze zrozumienie biblioteki, a co za tym idzie odpowiedzialniejszy dobór rozwiązań do napotkanych problemów.
Czym jest i jak działa DOM
Żeby przejść do bardziej ciekawych zagadnień działania React, należy przypomnieć sobie model DOM (ang. Document Object Model). Jest to w skrócie reprezentacja struktury dokumentu HTML w postaci drzewa obiektów w pamięci.
Każdy element kodu HTML ma swoje odzwierciedlenie w węzłach (ang. nodes), które z kolei mogą zawierać swoje atrybuty, tekst, czy nawet inne węzły. Poniżej znajduje się przykładowy kawałek kodu HTML oraz jego odzwierciedlenie w strukturze drzewa DOM:
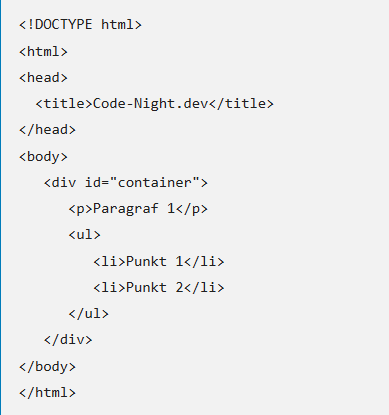
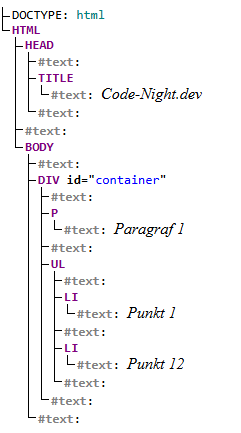
W praktyce DOM jest interfejsem API, który umożliwia manipulację tą strukturą za pomocą np. JavaScript. Pozwala na odczytywanie i modyfikowanie zawartości, struktury oraz styli strony.
A w jaki sposób w ogóle widzimy strony internetowe, takie jak ten blog? Dzieje się to w kilku krokach „pod maską” przeglądarki. Na początek dane HTML są pozyskiwane z serwera. Następnie są parsowane i konwertowane do postaci drzewa DOM. Później parsowane są także style CSS do postaci drzewa CSSOM (ang. CSS Object Model).
Kolejnym krokiem jest scalenie struktur DOM oraz CSSOM w Render Tree. Jest to proces, w którym drzewo DOM jest przechodzone od korzenia, przeszukując wszystkie widoczne węzły. Widoczny oznacza w tym przypadku węzeł, który nie ma atrybutu CSS display: none, ani nie jest tagiem typu <head>, <meta> czy <title>. Każdy element Render Tree otrzymuje przypisany zestaw odpowiadających mu atrybutów z drzewa CSSOM.
Następnie tworzony jest Layout, który powstaje poprzez obliczenia wykonywane w przeglądarce na podstawie Render Tree. Określane są dokładne rozmiary i pozycje wszystkich elementów. Proces ten nazywany jest także reflow.
Przedostatnim krokiem jest painting. W tym momencie wyniki obliczeń Layoutu zostają przekonwertowane na polecenia rysowania poszczególnych pikseli na ekranie. Ostatnim etapem jest display, czyli wyświetlanie obliczonych pikseli na ekranie.
Jak widać, cały proces może być kosztowny, jeśli chcielibyśmy przerenderowywać cały widok. Na szczęście dzięki interfejsowi DOM możemy ograniczać te operacje do minimum, np. do konkretnego znacznika <div> o id kontener-do-rerenderowania. Oczywiście, jeśli zmieni on całkowicie układ strony, część obliczeń otoczenia również zostanie przeprowadzona.
Wirtualny DOM w React
Znając już nieco zasadę procesów zachodzących w przeglądarce przy wyświetlaniu strony, możemy rozważyć następujący przypadek. Załóżmy, że chcemy dodać do <body> dokumentu 100 elementów <div>.
W czystym JavaScript nieoptymalny kod mógłby wyglądać tak:
for (let i = 0; i < 100; i++) {
const element = document.createElement('div');
element .textContent = `Div ${i}`;
document.body.appendChild(el);
}Każda iteracja spowodowałaby częściową aktualizację widoku – do modelu DOM zostanie dodany element, co wywołałoby mechanizm Layout Tree, częściową przebudowę Layoutu i odświeżenie widoku.
Oczywiście można by zoptymalizować kod przy użyciu document.createDocumentFragment, ale ręczne dbanie o optymalizację w dużej aplikacji byłoby uciążliwe. Ten fragment ma na celu nakreślić problem nadmiernych re-renderów.
Z pomocą przychodzi Virtual DOM – mechanizm, który w starszych wersjach React (<16) zarządzał renderowaniem. React nie manipuluje bezpośrednio oryginalnym drzewem DOM, co byłoby nieefektywne w dużych aplikacjach. Zamiast tego w pamięci przechowywana jest reprezentacja struktury drzewa DOM, która odzwierciedla jego układ i pozwala na szybsze manipulacje. Pierwsza kopia Virtual DOM powstaje przy pierwszym renderze komponentu.
Jeśli podczas działania aplikacji dojdzie do zmiany stanu komponentu lub komponent otrzyma nowe właściwości (propsy), React tworzy nową wersję struktury Virtual DOM dla danego komponentu oraz jego elementów potomnych. Następnie algorytm porównujący (diffing algorithm) sprawdza, które elementy w starym drzewie zmieniły się.
Zmiany są wykrywane m.in. poprzez:
- porównanie wartości atrybutów, np.
className,id, - sprawdzenie, czy typ elementu się nie zmienił, np. czy
<div>nie stał się<b>, - porównanie atrybutu
key, który jednoznacznie identyfikuje elementy listy.
Jeśli key lub typ elementu się zmieni, to algorytm porównujący uznaje go za nowy, a co za tym idzie usuwa poprzedni węzeł z drzewa i tworzy nowy. W przeciwnym wypadku aktualizuje tylko zmienione atrybuty i zachowuje istniejący węzeł DOM.
Warto też wspomnieć o atrybucie key – jest on szczególnie przydatny podczas tworzenia wszelkich list elementów. Dobrze wybrany unikalny klucz ułatwi Reactowi przeszukiwanie i dopasowanie elementów podczas porównywania starego i nowego drzewa wirtualnego DOM co pozytywnie wpływa na wydajność. Jeśli natomiast wybierzemy klucz i będzie on nieunikalny, to z wysokim prawdopodobieństwem skończy się to niepożądanymi efektami, takimi jak aktualizacja złych elementów listy, dlatego należy pamiętać o dobrym jego nadaniu.
A Jeśli zapomnimy o nim, to React poinformuje nas o tym w konsoli rzucając warning.

Więcej o kluczach i zasadach ich nadawania przeczytasz w osobnym wpisie poświęconym temu tematowi.
Rekonsyliacja i faza aktualizacji
Proces porównywania starego i nowego Virtual DOM nazywany jest rekonsyliacją (Reconciliation). Kiedy algorytm kończy działanie i wie już, co trzeba zmienić, React przechodzi do fazy aktualizacji. W tym momencie dodaje, usuwa i aktualizuje elementy wskazane podczas rekonsyliacji. Aktualizowane są także referencje (refs), a odpowiednie funkcje cyklu życia komponentów zostają wywołane. Po tym przeglądarka odświeża widok i widzimy finalny rezultat całego procesu.
Niestety wciąż nie było to najoptymalniejszy sposób odświeżania interfejsu, ponieważ praktycznie wszystko działo się synchronicznie, czyli raz rozpoczęty cykl nie mógł zostać przerwany do momentu zakończenia całej pracy. To przy bardzo rozbudowanych drzewach DOM mogło prowadzić do sytuacji, gdzie np. zdarzenia nie były w stanie się wykonać, ponieważ wciąż trwał proces aktualizacji, co skutkowało wrażeniem, że strona się zacina.
React Fibers
React 16 wprowadził nową implementację mechanizmu rekonsyliacji – Fiber, która umożliwia asynchroniczne renderowanie oraz wprowadzenie priorytetów zadań. Dzięki temu React może reagować płynniej na interakcje użytkownika i lepiej zarządzać większymi drzewami komponentów.
Fiber to struktura danych w postaci obiektu JavaScript, która reprezentuje jeden komponent Reacta. Przechowuje m.in. stan lokalny komponentu, właściwości (propsy), efekty do wywołania (lifecycle) oraz referencje do pierwszego dziecka (child), rodzeństwa (sibling) i rodzica (return). Ponieważ Fibery posiadają wzajemne referencje, mogą tworzyć drzewiastą strukturę – Fiber Tree, która powstaje przy pierwszym renderze komponentu.
Poniżej prezentuję jak wygląda prosta struktura Fiber dla kawałka kodu HTML:
<div>
<p>tekst</p>
<p>
<span>tekst</span>
</p>
<p>tekst</p>
</div>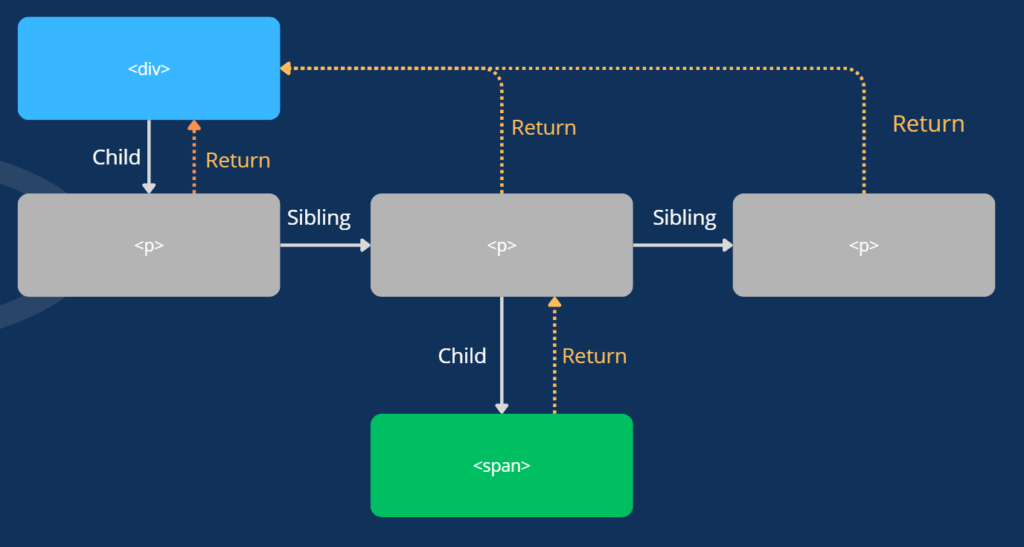
Jednostka pracy i fazy działania algorytmu Fiber
Każdy węzeł Fiber stanowi jednostkę pracy. React przetwarza aplikację właśnie poprzez wykonywanie pracy na tych jednostkach w ramach Render Phase, która jest asynchroniczna i obsługuje zadania o różnych priorytetach. Praca może zostać wstrzymana lub anulowana, jeśli przeglądarka musi obsłużyć ważniejsze zdarzenia, np. obsługę zdarzeń użytkownika.
W tej fazie następuje także porównanie nowych wyników pracy z poprzednim drzewem, a także tworzenie lub aktualizacja nowej wersji każdego węzła. Wszystkie operacje dzieją się w pamięci, bez wprowadzania zmian w rzeczywistym DOM.
Praca w środku Reacta jest wykonywana wewnątrz pętli workLoop, która iteruje po kolejnych jednostkach pracy. Dla każdego z węzłów wywoływane są dwie kluczowe funkcje – beginWork oraz completeWork. Funkcja beginWork odpowiada za przetwarzanie danego węzła Fiber, wywołuje funkcję komponentu, tworzy lub aktualizuje dzieci węzła, porównuje wynik z poprzednim drzewem oraz ustala, jakie zmiany należy wprowadzić w kolejnej fazie. Funkcja completeWork jest wywoływana po przetworzeniu wszystkich dzieci węzła i odpowiada za końcowe obliczenia dla danego Fiber, przygotowując efekty do commit phase oraz scalając efekty dzieci w tzw. effect list. Dzięki takiej organizacji React może wstrzymać pracę w dowolnym momencie i wznowić ją później, co pozwala obsłużyć zadania o wyższym priorytecie bez blokowania interfejsu.
Wynikiem wszystkich prac przeprowadzonych na Fiber Tree w fazie renderowania jest nowa struktura Work-in-progress Tree, która zawiera aktualny stan komponentów, planowane zmiany względem starego drzewa, a także informacje o efektach, jakie mają zostać wykonane (na przykład tworzenie nowych elementów DOM czy wywołanie metod lifecycle, np. useEffect).
Poniżej zamieściłem poprzedni diagram Fibers Tree, tym razem zaopatrzony w kolejność przechodzenia przez niego algorytmu:
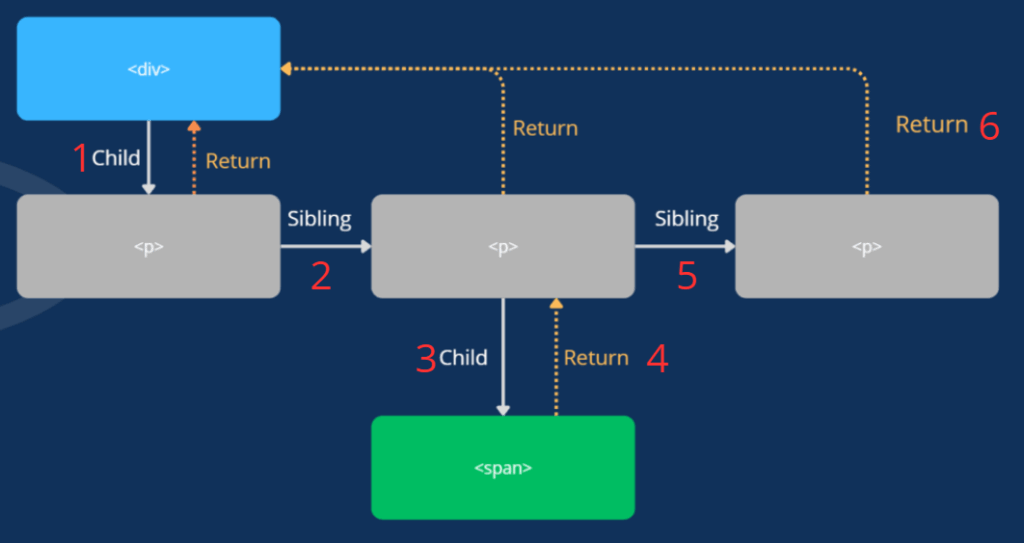
Kiedy Work-in-progress Tree jest już gotowe, jest przekazywane do fazy commit (Commit Phase). Podczas niej React stosuje wszystkie zaplanowane efekty z listy efektów, wprowadza zmiany w drzewie DOM oraz uruchamia metody lifecycle. Po zakończeniu aktualizacji następuje jeszcze przepięcie wskaznika obecnego stanu drzewa na Work-in-progress Tree – od tego momentu staje się ono najbardziej aktualnym drzewem Fiberów. Ta faza jest synchroniczna i powoduje już widoczne zmiany dla użytkownika.
Podsumowanie
Dzięki mechanizmowi Fiber React jest w stanie efektywnie zarządzać aktualizacjami, minimalizować koszty renderowania i zapewniać płynne działanie aplikacji nawet przy dużych drzewach komponentów. Zrozumienie tych mechanizmów pozwala świadomie korzystać z Reacta, unikać niepotrzebnych re-renderów i z pewnością, jak sam zobaczysz, przyda się w zrozumieniu kolejnych zagadnień pracy z tą biblioteką.
Świetny artykuł, dobre i proste wyjaśnienie poszczególnych funkcjonalności – czyt. mega zrozumiałe dla każdego 🙂